recurrent neural network¶
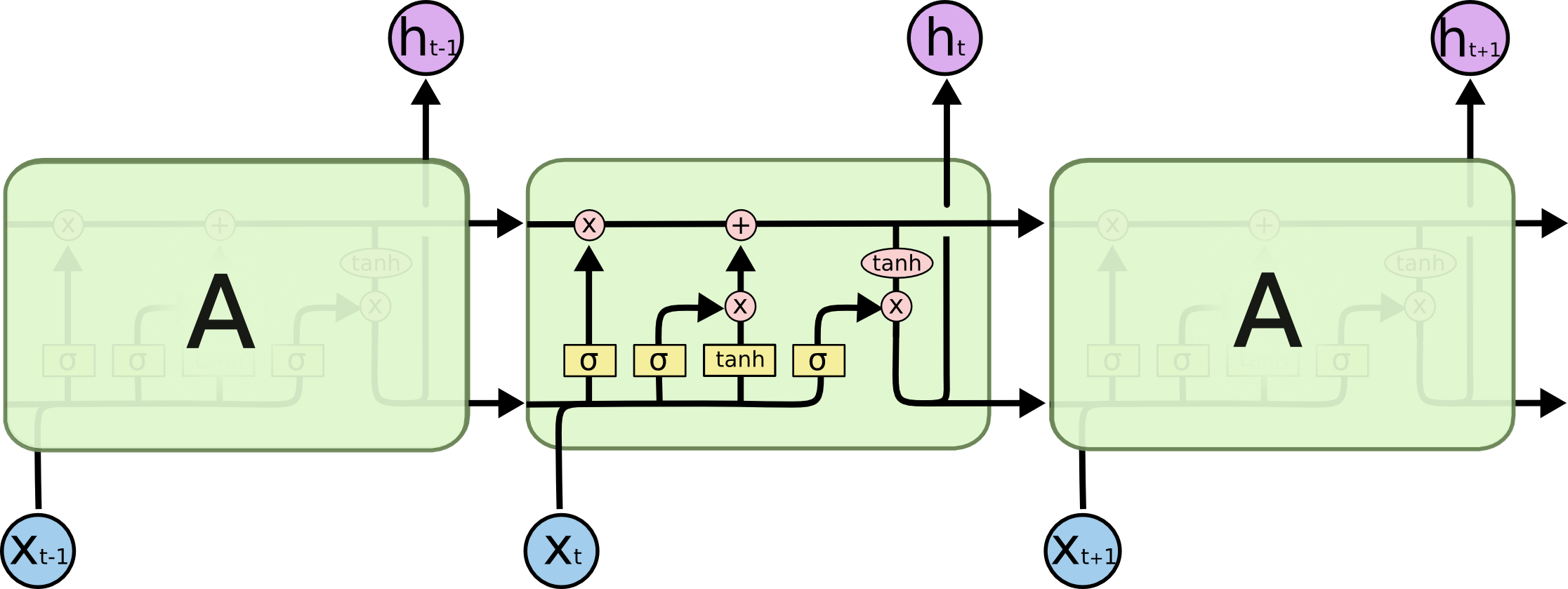
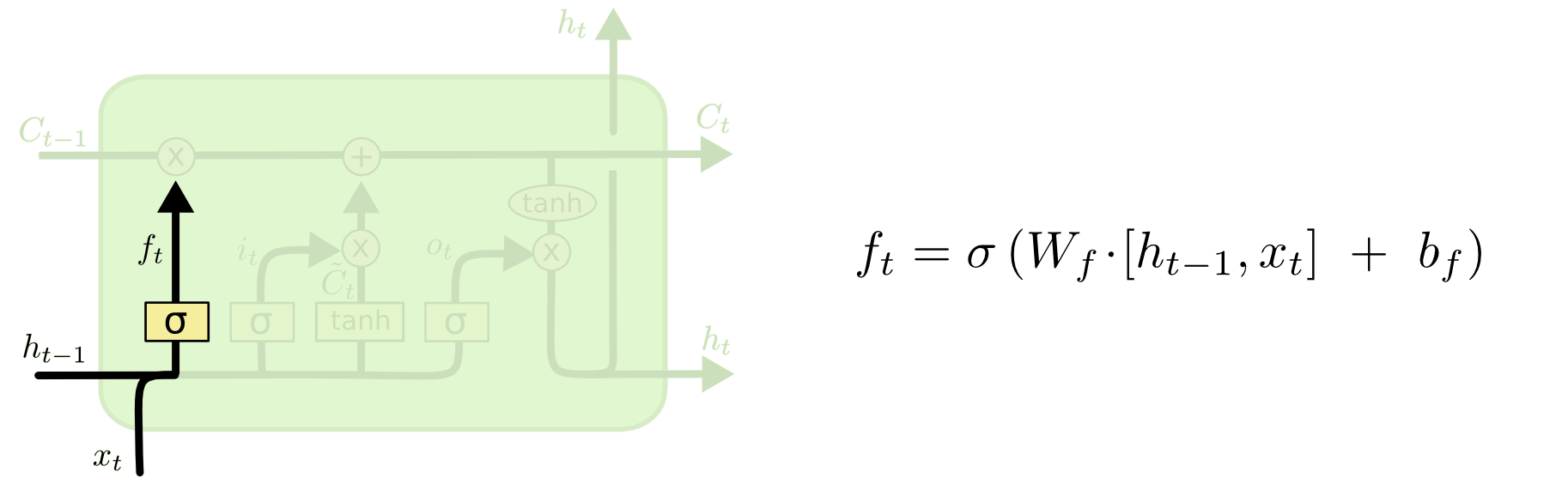
This notebook's LSTM part is a shortened (and simplified) version of colah's blog.
1. why recurrent neural network, and what is it¶
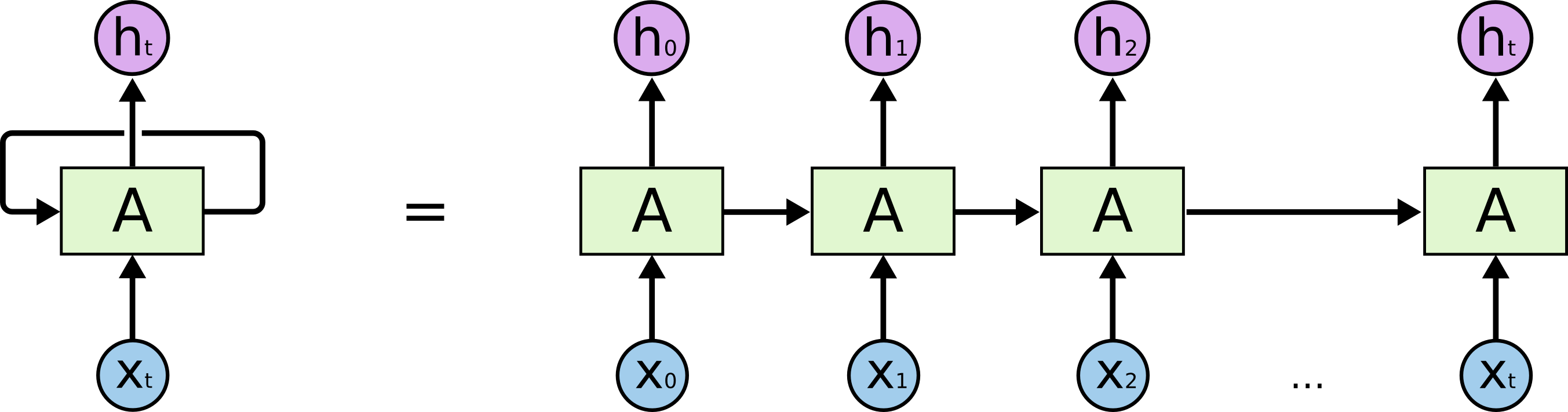
Because processing of sequence data is incremental: the understanding of the current information is always based on information in the past. Like natural language, or timeseries: our understanding of the new word / new data point is based on information gained from previous words or data. The process of cumulating information from each record is recurrent: one processing center (e.g., our brain) uses its own output from the previous cycle as input to the current cycle. Graphically it's commonly depicted with a loop:

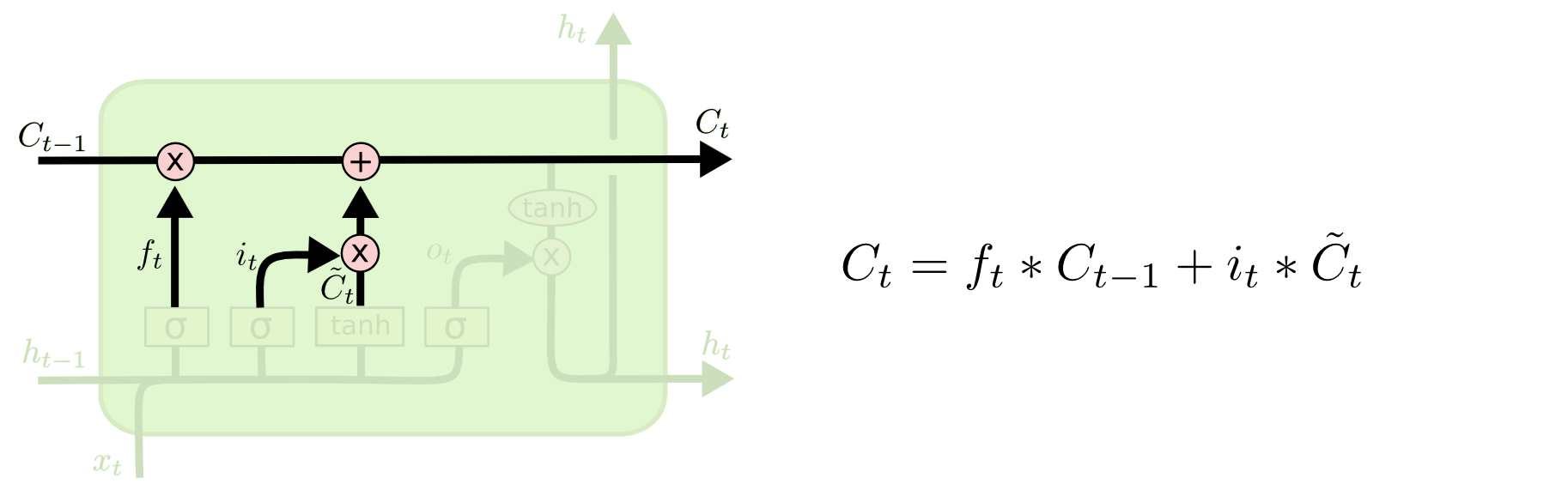
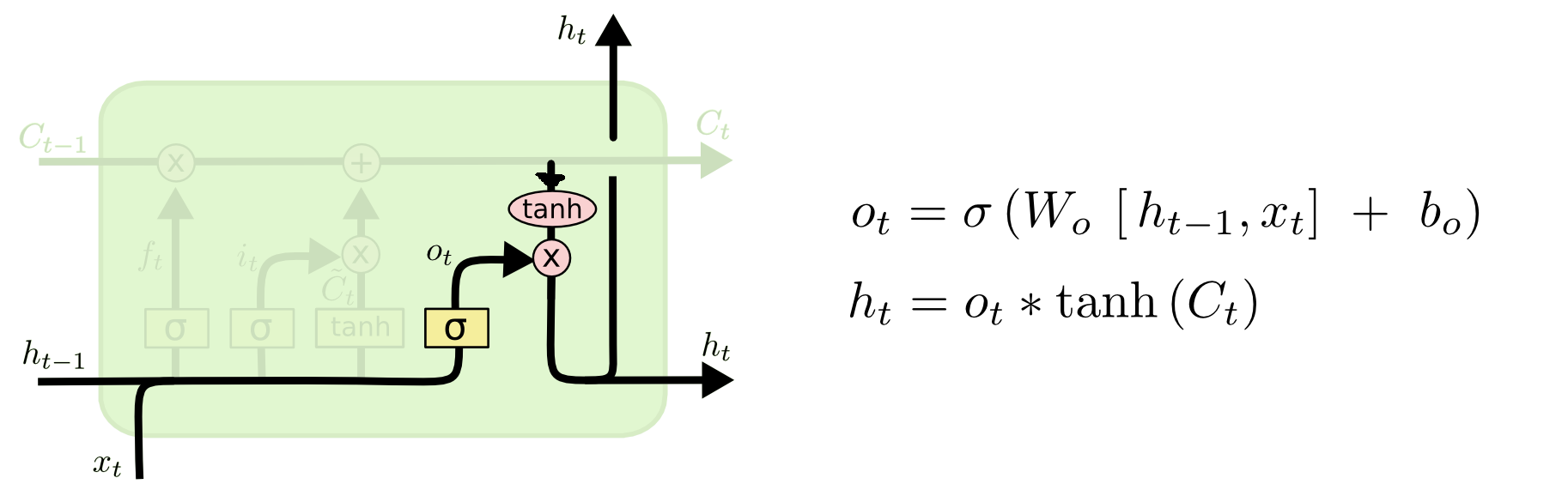
$x$ is the input sequence, $h$ is the output sequence, or understanding of the input sequence. $t$ denotes the position of the element in the sequence, or we can also say the element we receive at the current time $t$. $A$ is the processing center, i.e., the model or our brain.
Another common way to depict the temporal dimension of recurrent processing is to unroll it along the timeline: